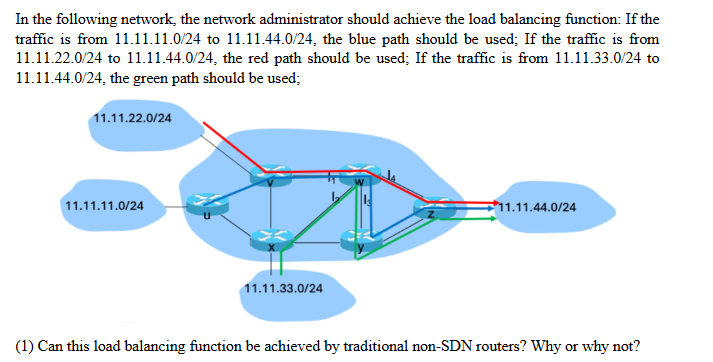
# 1.SDN
- RIP(Routing Information Protocol):
基本原理:RIP 使用一种称为 距离向量(Distance Vector) 的路由算法。它通过跳数(hop count)来衡量到达目标网络的距离,跳数即从一个路由器到目标网络需要经过的路由器数量。
特点:
- 跳数限制:RIP 的最大跳数为 15,跳数达到 16 被视为不可到达。这意味着 RIP 适用于较小的网络。
- 更新频率:RIP 每 30 秒向其邻居广播路由表更新信息,这样做会增加网络负载,尤其是在大型网络中。
- 收敛速度慢:因为 RIP 需要依靠定期更新,所以在网络拓扑发生变化时,其收敛速度较慢。
- 版本:RIP 有两个版本,RIP v1(不支持子网掩码)和 RIP v2(支持子网掩码,增加了安全和效率特性)。
适用场景:由于 RIP 的跳数限制和较慢的收敛时间,它通常适用于小型或中型网络。
- OSPF(Open Shortest Path First):
基本原理:OSPF 是一种链路状态(Link State) 路由协议,它通过一种称为 Dijkstra 算法的链路状态算法来计算最短路径。OSPF 可以基于多种因素(如带宽、延迟、链路成本)计算最佳路径,而不仅仅依赖于跳数。
特点:
- 无跳数限制:OSPF 没有跳数限制,适用于大型复杂的网络。
- 区域划分:OSPF 将大型网络划分为多个区域(Area),这样有助于降低网络复杂性,减少路由表规模,提高路由效率。
- 快速收敛:OSPF 具有快速的收敛特性。当网络拓扑发生变化时,OSPF 能够迅速检测到变化,并重新计算最佳路径。
- 成本计算:OSPF 使用基于带宽的成本来计算最佳路径,网络管理员可以配置链路的成本值来优化路由选择。
- 多播更新:与 RIP 的广播不同,OSPF 使用多播(multicast)来传播链路状态信息,降低了不必要的网络流量。
适用场景:OSPF 适用于中型到大型网络,特别是在需要复杂路由选择和快速收敛的情况下。
而 SDN,也就是软件定义网络(Software-Defined Networking),是一种让网络更 “智能” 和 “灵活” 的新技术。通俗地说,它打破了传统网络的限制,使得我们能够像编写软件一样,灵活地控制网络中的设备。
通俗解释:
传统网络是怎么工作的?
- 在传统网络中,路由器和交换机这样的设备自己做决策,决定数据从哪里进、到哪里出。每个设备都有自己的 “大脑”(控制系统),它们通过自己内部的规则来决定如何转发数据。
- 这种方式的缺点是:每台设备只能知道自己周围的一些情况,无法掌控整个网络。因此,管理网络变得很复杂,如果要改变某个地方的流量,可能需要逐一配置很多设备。
SDN 是怎么做的?
- SDN 通过把网络设备的 “大脑” 集中起来,统一用一个 “中央控制器” 来控制所有网络设备。这就像有一个总指挥官,能看到整个网络的全貌,并能迅速决定数据的最佳传输路径。
- 数据设备变成 “执行者”:路由器和交换机不再自己做决定,而是听从控制器的指令,负责把数据按照命令发送到正确的地方。
为什么 SDN 更好?
- 灵活控制:就像编写程序一样,管理员可以通过软件定义网络流量,自动化配置,而不需要手动去调整每个设备的设置。
- 全局视角:控制器能看到整个网络的流量情况,能够根据实时情况动态调整,比如:在某个地方流量很大时,可以自动分流到其他路径。
- 自动化管理:可以编写规则,自动化处理网络中的问题,比如检测到网络拥塞时,可以自动调整路由来缓解压力。
# 2.TCP
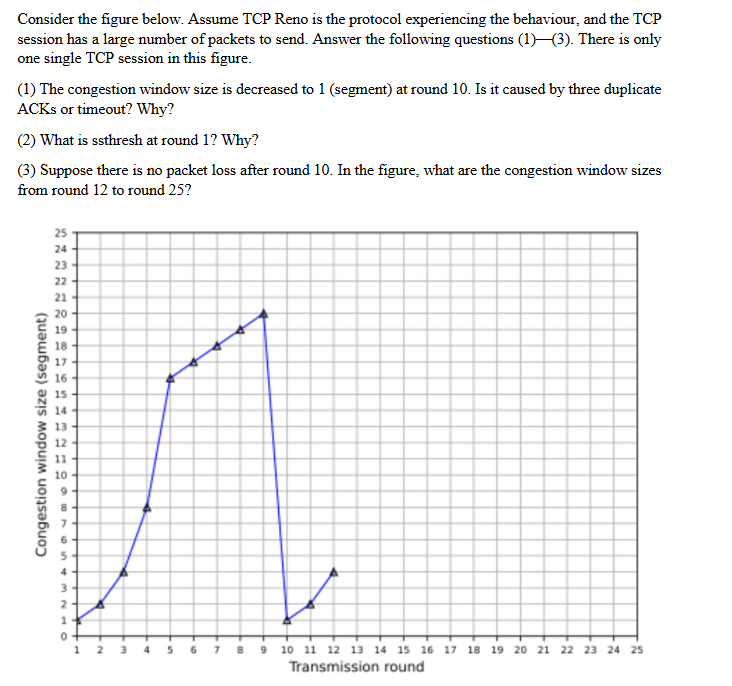
TCP Reno 是一种 TCP(传输控制协议) 拥塞控制算法,是经典 TCP Tahoe 算法的改进版本。TCP Reno 主要优化了拥塞检测和恢复过程,特别是在数据丢包后的表现。它通过在检测到丢包时引入 快速恢复(Fast Recovery) 和 快速重传(Fast Retransmit) 机制,使得丢包后的恢复效率更高。
# TCP Reno 的主要特性:
慢启动(Slow Start):
- 当连接开始或检测到网络超时时,拥塞窗口(cwnd) 从较小值(通常是 1 个 MSS,即最大报文段)开始,随着每次接收到 ACK 后,cwnd 以指数增长的方式逐渐增大,直到达到一个阈值(ssthresh,慢启动阈值)。
拥塞避免(Congestion Avoidance):
- 当 cwnd 增长到超过 ssthresh 时,TCP 进入拥塞避免阶段,cwnd 不再指数增长,而是线性增长,每个 RTT(往返时间)增加 1 个 MSS。这一机制能够更平缓地增加发送速率,减少网络拥塞的风险。
快速重传(Fast Retransmit):
- 当发送方接收到 3 个重复的 ACK 时,TCP Reno 假设网络发生了丢包,而不是等到超时来判断丢包。这时,TCP Reno 会立即重传该丢失的数据段,而不等待超时,从而提高丢包后的响应速度。
快速恢复(Fast Recovery):
- 在 TCP Tahoe 中,丢包后会将 cwnd 立即减小到 1MSS,然后重新进入慢启动阶段。但 TCP Reno 在检测到 3 个重复的 ACK 后,会将 cwnd 减半(进入快速恢复),然后进入线性增长的拥塞避免阶段,而不是回到慢启动。这一优化使得 TCP Reno 在处理丢包时更加高效,不会像 Tahoe 一样大幅降低传输速度。
# TCP Reno 的工作流程:
- 初始阶段:从慢启动开始,cwnd 呈指数增长,直到达到 ssthresh。
- 拥塞避免:一旦 cwnd 达到 ssthresh,cwnd 以线性速度增长。
- 丢包检测:当接收到 3 个重复 ACK 时,TCP Reno 立即触发快速重传。
- Congestion 发生后 (lost packet)
1)timeout- cwnd=1,ssthresh 变为当前 cwnd 的一半,并从 slow start 开始
2) dup - cwnd 变为 lost packet 时的一半,并从 addtive increase 即拥塞避免开始
- cwnd=1,ssthresh 变为当前 cwnd 的一半,并从 slow start 开始
- 快速恢复:cwnd 减半,进入快速恢复阶段,避免完全进入慢启动。
# 与 TCP Tahoe 的区别:
- TCP Tahoe 在丢包时会将 cwnd 直接减小到 1,并重新进入慢启动阶段。
- TCP Reno 则引入了快速恢复机制,丢包时不再完全进入慢启动,而是减半 cwnd 并进入线性增长的拥塞避免阶段,这显著减少了网络中的恢复时间。
TCP Reno 由于其更加高效的丢包恢复机制,成为 TCP 协议中较为常用的拥塞控制算法之一,尤其适用于高延迟、大带宽的网络环境。
# P2P
file distribution: 把文件发给 N 个主机