# 查询处理的基本步骤
# 1. 查询处理的主要问题
- 查询处理包含以下三个关键问题:
- 如何将 SQL 查询转换为 DBMS 理解的形式(处理阶段)。
- 如何找到执行查询的最佳策略(优化阶段)。
- 执行查询的具体标准是什么(执行阶段)。
# 2. DBMS 的内部结构
- 组件概览:包括前端应用接口、SQL 接口、查询处理和优化引擎、事务管理器、并发控制、文件和访问方法、缓冲管理器和磁盘空间管理器。
- 查询处理和优化引擎负责将 SQL 命令转换为可执行的查询计划,并通过优化选择最低成本的查询执行方式。
- 系统目录存储数据库的元数据,辅助查询优化和执行。
# 3. 查询处理的基本步骤
- 步骤 1:解析与转换
- 检查 SQL 语法和语义,将 SQL 查询转换为关系代数表达式(逻辑查询计划)。
- 例如,将视图替换为实际子查询。
- 步骤 2:查询优化
- 通过启发式方法重组查询,最小化中间结果的大小。
- 选择具有最低成本的查询计划,并根据成本估算选择最优的执行策略。
- 步骤 3:查询执行
- 执行查询计划中的操作,例如在执行树中使用不同的操作算法。
# 4. 查询处理示例
- 示例查询:
SELECT name FROM student NATURAL JOIN enrolled WHERE uosCode='COMP9120'; - 转换为关系代数表达式:按条件选择、投影、连接等步骤分解成关系代数操作。
- 查询执行计划:使用嵌套循环、索引扫描、表访问等方式执行查询。
# 查询优化
# 逻辑查询计划:基于启发式的优化
# 1. 等价代数表达式
- 提出了通过代数表达式将 SQL 查询转换为逻辑查询计划的概念,目标是确保等价转换的正确性和提高执行效率。
- 强调了逻辑操作层面的转换规则,并举例展示了如何将初始查询表示为等价的代数表达式查询优化策略
- 启发式优化(Heuristic Optimization):通过重新排列查询树中的操作顺序来减少中间结果大小。
- 例如,优先执行选择和投影操作,以尽量缩小参与连接的关系大小。
- 代数转换规则:应用一系列代数规则进行等价转换,优化执行计划。例如:
- 投影级联:通过级联操作消除多余的属性。
- 选择级联:将选择条件合并,以减少筛选操作次数 。
# 2. - 选择分布律:可以将选择条件在连接之前应用到各个关系上,以减少连接的复杂度。
1 | - 示例:对于查询`SELECT * FROM Deposit, Customer, Branch WHERE Customercity='Sydney'`,可将条件`Customercity='Sydney'`应用于`Customer`表,从而减少最终的连接操作 。 |
- 投影优化:尽可能不必要的属性,降低数据处理量。
- 示例展示了在查询执行中尽量早地移除不需要的列,从而优化整体查询性能 。
# 4. 查询优化规则总结
- 提出了五条 1. 连接交换律:R1 ⋈ R2 = R2 ⋈ R1 2. 连接结合律:((R1 ⋈ R2) ⋈ R3) = (R1 ⋈ (R2 ⋈ R3)) 3. 投影级联:若属性集
B1, ..., Bn是属性集A1, ..., An的子集,则ΠB1,...,Bn (ΠA1,...,An (R)) = ΠB1,...,Bn (R)4. 选择级联:σΘ1 (σΘ2 (R)) = σΘ1∧Θ2 (R) 5. 选择分布律:σθ(R1 ⋈ R2) = (σθ(R1)) ⋈ R2 。
# 5. 投影和选择的进一步优化
- 投影优化策略可以通过剔除据量。
- 选择操作的分布则可以减少参与连接的记录数量,有助于提高执行效率。
- 这些优化策略的目标是减少查询的中间结果大小,从而优化 I/O 成本 。
# 物理查询计划:成本估算优化
# 1. 物理查询计划 (Physical Query Plan)
- 物理查询计划将逻辑查询操作转化为实际的执行步骤,包含具体的算法选择。主要目标是通过优化 I/O 操作来找到最低成本的执行计划查询执行计划 (Query Execution Plan)
- 查询执行计划是一种详细的评估策略,使用物理操作符来指定查询的实际执行方式。
- 例如,给定自然连接的关系 R (A,B,C) 和 S (C,D),可以通过索引扫描、表扫描和嵌套循环连接等方式实现查询操作 。
# 3. - 查询优化器会计算不同执行计划的成本,主要通过 I/O 操作数来估算代价。
- 影响成本的因素包括可用的访问方法(如索引、扫描)和数据的物理组织方式(如数据是否排序) 。
# 4. 连接操作 (Joi - 嵌套循环连接(Nested Loop Join):适用于任意连接条件,但在 I/O 方面代价较高。需要逐一扫描每一页来查找匹配项。
- (Nested Loop Join)
![]()
![]()
- 块嵌套循环连接(Block-Nested Loop Join):优化了嵌套循环连接,通过一次加载块中的多条记录来减少内层扫描次数 。


- 工作原理
块嵌套循环连接是对简单嵌套循环连接的优化。通过将外表的数据分块,可以减少内层扫描的次数,降低 I/O 成本。
- 具体步骤:
- 将外表 RRR 分成多个块(block),每个块可以包含多个页面(page)。
- 将一个块加载到内存中,然后遍历内表 SSS 的所有页面。
- 对于内表 SSS 中的每条记录,检查是否有匹配的外表记录。
- 若匹配,将结果加入到结果集中。
- 重复以上步骤,直到外表的所有块都处理完毕。
- I/O 成本
假设:
- 外表 RRR 有 bRb_RbR 个页面。
- 内表 SSS 有 bSb_SbS 个页面。
- 内存可容纳 MMM 个页面。
总的 I/O 成本为:
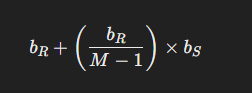
其中:
- bRb_RbR 表示首次将外表 RRR 加载到内存的成本。
- bRM−1\frac{b_R}{M - 1}M−1bR 表示将外表 RRR 分成的块数,因为内存中一个块最多可以放 M−1M - 1M−1 个页面。
- 每个块都需要扫描内表 SSS 一次,因此需要乘以 bSb_SbS。
- 优缺点
- 优点:
- 通过分块减少了内层扫描的次数,比简单嵌套循环连接效率更高。
- 适合内存较大的情况,因为更多的内存可以容纳更大的块,从而减少内表的扫描次数。
- 缺点:
- 如果内存较小,块的大小受限,效果不如预期。
- 对于特别大的数据集,仍然可能需要大量的 I/O 操作。
- 应用场景
块嵌套循环连接适用于没有索引且内存相对充足的情况。特别是在数据量大而内表没有索引时,块嵌套循环连接是一个不错的选择。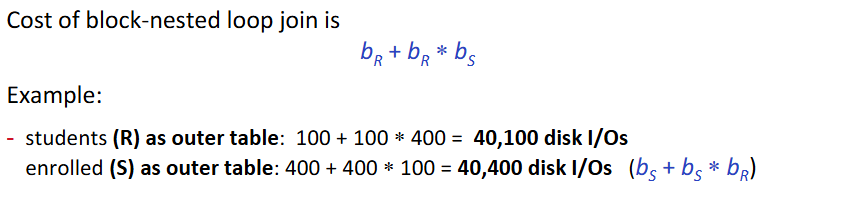
- 索引嵌套循环连接(Index-Neste):利用内层表的索引来查找外层表的匹配记录。此方法的成本主要由外层表的页数和索引查找成本组成 。
- 工作原理
索引嵌套循环连接是利用内表的索引来优化嵌套循环连接。每次在外表中读取一条记录时,不需要扫描内表的所有记录,而是通过索引直接找到匹配记录。
2. 具体步骤:
1. 对于外表 RRR 中的每条记录 rrr,使用内表 SSS 上的索引查找与 rrr 匹配的记录。
2. 如果找到匹配的记录,将匹配的记录对加入结果集。
3. 重复此操作,直到外表 RRR 的所有记录都处理完毕。
- I/O 成本
假设:
- 外表 RRR 有 bRb_RbR 个页面,总记录数为 TRT_RTR。
- 内表 SSS 有索引,访问索引的成本为 CCC(通常表示为读取索引和数据页的 I/O 成本)。
总的 I/O 成本为:
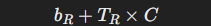
其中:
- bRb_RbR 是读取外表的 I/O 成本。
- TR×CT_R \times CTR×C 表示对每条外表记录,通过索引在内表中查找匹配记录的 I/O 成本。
- 优缺点
- 优点:
- 当内表有索引时,索引嵌套循环连接能显著降低 I/O 成本,因为它不需要对内表进行全表扫描。
- 适合等值连接(Equality Join),因为索引可以快速定位特定值。
- 缺点:
- 需要内表上有合适的索引。如果内表没有索引,则索引嵌套循环连接的效率会很低。
- 对于范围连接(如
BETWEEN操作),性能优势不如等值连接明显,因为范围查询可能需要扫描多个索引条目。
- 应用场景
索引嵌套循环连接适用于以下情况:
- 外表的记录数相对较少,而内表有适合的索引。
- 需要进行等值连接的场景,如主键 - 外键连接。
![]()

# 5. 外部排序算法
- 外部合并排序(External):用于对数据进行外部排序,适用于内存不足的情况。算法包括两个主要步骤:
- 创建有序的分段(sorted runs):将数据分块加载到内存,进行内部排序后写回磁盘。
- 合并有序分段:逐次合并多个有序分段,最终生成完整的有序数据 。
# 外部合并排序的基本思想
外部合并排序通过以下两个阶段来完成排序任务:
- 划分阶段(Partition Phase 或 Run Generation Phase):将大文件分成多个可以放入内存的小块(称为 “有序分段”)。
- 合并阶段(Merge Phase):将这些小块逐次合并,最终生成一个有序的大文件。
# 外部合并排序的具体步骤
# 1. 划分阶段(生成有序分段)
- 将整个数据集分为若干小块,每块的大小不超过内存容量。
- 将每一块数据加载到内存中,并在内存中完成排序(例如使用快速排序或堆排序等内部排序算法)。
- 将排序后的数据块(有序分段)写回磁盘。
- 最终,得到多个已经排序好的小文件(有序分段),每个分段的大小不超过内存容量。
示例:假设我们有 1000 万条记录,内存只能容纳 100 万条记录。
- 将 1000 万条记录分为 10 个小分段,每个分段包含 100 万条记录。
- 将每个分段加载到内存中进行排序,然后写回磁盘,生成 10 个有序的分段文件。
# 2. 合并阶段(逐层合并有序分段)
- 将有序的分段逐层合并,直到最终生成一个完整的有序文件。
- 合并时通常使用多路归并(k-way merge),即每次合并多个有序分段(通常是根据内存容量决定 k 的值)。
- 每次合并的结果生成一个新的有序文件,重复此过程,直到所有分段合并为一个最终的有序文件。
示例:
- 继续以上的例子,10 个分段可以一次性加载 5 个到内存(假设内存可以同时容纳 5 个分段进行多路归并)。
- 第一次合并,将 10 个分段两两合并成 5 个更大的有序分段。
- 再次合并,直到最终得到一个完整的有序文件。
# I/O 成本分析
外部合并排序的 I/O 成本主要来源于多次读取和写回分段的操作。总的 I/O 成本大致为:
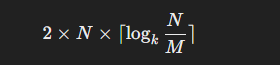
其中:
- N 是数据总量的页面数。
- M 是内存能容纳的页面数。
- k 是内存中可容纳的分段数(即每次可以合并的分段数)。
# 外部合并排序的优点
- 高效处理超大数据集:外部合并排序可以对超过内存大小的数据进行排序,非常适合磁盘操作。
- 多路归并减少合并次数:每次合并尽可能多的分段,可以减少 I/O 操作次数,从而提高排序效率。
# 外部合并排序的缺点
- 高 I/O 开销:频繁的磁盘读写会带来较高的 I/O 成本,特别是在磁盘速度较慢的情况下。
- 需要足够的磁盘空间:在合并阶段,算法需要额外的磁盘空间存储中间结果文件。
# 应用场景
外部合并排序广泛应用于需要处理大规模数据的场景,包括:
- 数据库的排序操作(如
ORDER BY子句)。 - 大数据处理系统中的排序任务。
- 操作系统在内存不足时进行的文件排序。
# 6. 管道和物化 (Pipelining and Materialization)
aterialization)**:逐步计算每个操作并将结果存储在临时关系中。此方法适用于简单的查询计划,但会增加 I/O 成本。
- 管道(Pipelining):直接将一个操作的输出作为下一个操作的输入,减少了临时存储的需求,适用于较为复杂的查询 。